

| Model Browser User's Guide | |
Two-Stage Models
To unite the two models, it is first necessary to review the distributional assumptions pertaining to the response feature vector pi. The variance of pi (Var(pi)) is given by
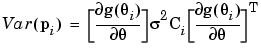
|
(6-11) |
For the sake of simplicity, the notation 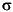 2Ci is to denote Var(pi). Thus, pii is distributed as
2Ci is to denote Var(pi). Thus, pii is distributed as
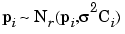
|
(6-12) |
where Ci depends on fi through the variance of 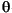 i and also on gi through the conversion of i to the response features pi. Two standard assumptions are used in determining Ci: the asymptotic approximation for the variance of maximum likelihood estimates and the approximation for the variance of functions of maximum likelihood estimates, which is based on a Taylor series expansion of gi. In addition, for nonlinear
i and also on gi through the conversion of i to the response features pi. Two standard assumptions are used in determining Ci: the asymptotic approximation for the variance of maximum likelihood estimates and the approximation for the variance of functions of maximum likelihood estimates, which is based on a Taylor series expansion of gi. In addition, for nonlinear 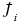 or gi, Ci depends on the unknown i ; therefore, we will use the estimate
or gi, Ci depends on the unknown i ; therefore, we will use the estimate 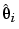 in its place. These approximations are likely to be good in the case where 2 is small or the number of points per sweep (mi) is large. In either case we assume that these approximations are valid throughout.
in its place. These approximations are likely to be good in the case where 2 is small or the number of points per sweep (mi) is large. In either case we assume that these approximations are valid throughout.
We now return to the issue of parameter estimation. Assume that the 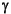 i are independent of the
i are independent of the 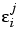 . Then, allowing for the additive replication error in response features, the response features are distributed as
. Then, allowing for the additive replication error in response features, the response features are distributed as
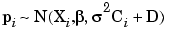
|
(6-13) |
When all the tests are considered simultaneously, equation (6-13) can be written in the compact form
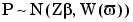
|
(6-14) |
where P is the vector formed by stacking the n vectors pi on top of each other, Z is the matrix formed by stacking the n Xi matrices, W is the block diagonal weighting matrix with the matrices on the diagonal being 2Ci+D , and 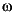 is a vector of dispersion parameters. For the multivariate normal distribution (6-14) the negative log likelihood function can be written
is a vector of dispersion parameters. For the multivariate normal distribution (6-14) the negative log likelihood function can be written
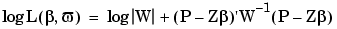
|
(6-15) |
Thus, the maximum likelihood estimates are the vectors 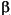 ML and ML that minimize logL(,).Usually there are many more fit parameters than dispersion parameters; that is, the dimension of is much larger than . As such, it is advantageous to reduce the number of parameters involved in the minimization of logL(,). The key is to realize that equation (6-15) is conditionally linear with respect to . Hence, given estimates of , equation (6-15) can be differentiated directly with respect to and the resulting expression set to zero. This equation can be solved directly for as follows:
ML and ML that minimize logL(,).Usually there are many more fit parameters than dispersion parameters; that is, the dimension of is much larger than . As such, it is advantageous to reduce the number of parameters involved in the minimization of logL(,). The key is to realize that equation (6-15) is conditionally linear with respect to . Hence, given estimates of , equation (6-15) can be differentiated directly with respect to and the resulting expression set to zero. This equation can be solved directly for as follows:
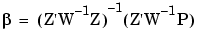
|
(6-16) |
The key point is that now the likelihood depends only upon the dispersion parameter vector , which as already discussed has only modest dimensions. Once the likelihood is minimized to yield ML , then, since W(ML) is then known, equation (6-16) can subsequently be used to determine ML.
| | Global Models | Prediction Error Variance for Two-Stage Models | |