

| Curve Fitting Toolbox | |
Sectioning
Sectioning involves specifying a range of response data or a range of predictor data to exclude. You might want to section a data set because different parts of the data set are described by different models or many contiguous data points are corrupted by noise, large systematic errors, and so on.
Sectioning data with the Curve Fitting Toolbox follows these rules:
To exclude multiple sections of data, you can use the excludedata function from the MATLAB command line.
Two examples of sectioning by domain are shown below for generated data.
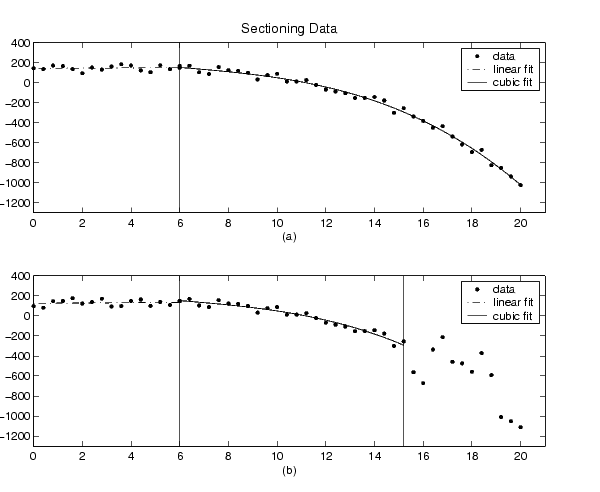
Plot (a) shows the data set sectioned by fit type. The left section is fit with a linear polynomial, while the right section is fit with a cubic polynomial. Plot (b) shows the data set sectioned by fit type and by valid data. Here, the rightmost section is not part of any fit because the data is corrupted by noise. Note that reproducing these plots using the toolbox is a multistep process. For example, to reproduce plot (a), the steps are
| | Marking Outliers | Example: Excluding and Sectioning Data | |