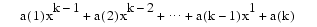| Spline Toolbox | |
Introduction
This glossary provides brief definitions of the basic mathematical terms and notation used in this guide. But, in contrast to standard glossaries, the terms do not appear here in alphabetical order. This is not much of a disadvantage since the glossary is quite short (and all the terms appear in the Index in any case). The order is carefully chosen to have the explanation of each term only use terms discussed earlier.
In this way, you may, the first time around, choose to read the entire glossary from start to finish, for a cohesive introduction to these terms.
Intervals
Since MATLAB uses the notation [a,b] to indicate a matrix with the two columns, a and b, we use in this guide the notation [a .. b] to indicate the closed interval with endpoints a and b. We do the same for open and half-open intervals. For example, [a .. b) denotes the interval that includes its left endpoint, a, and excludes its right endpoint, b.
Vectors
A d-vector is a list of d real numbers, i.e., a point in Rd. In MATLAB, a d-vector is stored as a matrix of size [1,d], i.e., as a row-vector, or as a matrix of size [d,1], i.e., as a column-vector. In this toolbox, vectors are column vectors.
Functions
In this toolbox, the term function is used in its mathematical sense, and so describes any rule that associates, to each element of a certain set called its domain, some element in a certain set called its target. Common examples in this toolbox are polynomials and splines. But even a point x in Rd, i.e., a d-vector, may be thought of as a function, namely the function, with domain the set {1,...,d} and target the real numbers R, that, for i=1:d, associates to i the real number x(i).
The range of a function is the set of its values.
We distinguish between scalar-valued and vector-valued functions. Scalar-valued functions have the real numbers R (or, more generally, the complex numbers) as their target, while d-vector-valued functions have Rd as their target. We also distinguish between univariate and multivariate functions. The former have some real interval, or, perhaps, all of R as their domain, while m-variate functions have some subset, or perhaps all, of Rm as their domain.
Placeholder notation
If f is a bivariate function, and y is some specific value of its second variable, then
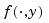
is the univariate function whose value at x is f(x,y).
Curves and surfaces vs. functions
In this toolbox, the term function usually refers to a scalar-valued function. A vector-valued function is called here a:
curve if its domain is some interval
surface if its domain is some rectangle
To be sure, to a mathematician, a curve is not a vector-valued function on some interval but, rather, the range of such a (continuous) function, with the function itself being just one of infinitely many possible parametrizations of that curve.
Tensor products
A bivariate tensor product is any weighted sum of products of a function in the first variable with a function in the second variable, i.e., any function of the form
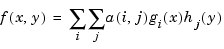
More generally, an m-variate tensor product is any weighted sum of products
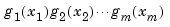 of m univariate functions.
of m univariate functions.
Polynomials
A univariate scalar-valued polynomial is specified by the list of its polynomial coefficients. The length of that list is the order of that polynomial, and, in this toolbox, the list is always stored as a row vector. Hence an m-list of polynomials of order k is always stored as a matrix of size [m,k].
The coefficients in a list of polynomial coefficients are listed from "highest" to "lowest", to conform to the MATLAB convention, as in the command polyval(a,x). To recall: assuming that x is a scalar and that a has k entries, this command returns the number
In other words, the command treats the list a as the coefficients in a power form. For reasons of numerical stability, such a coefficient list is treated in this toolbox, more generally, as the coefficients in a shifted, or, local power form, for some given center c. This means that the value of the polynomial at some point x is supplied by the command polyval(a,x-c).
A vector-valued polynomial is treated in exactly the same way, except that now each polynomial coefficient is a vector, say a d-vector. Correspondingly, the coefficient list now becomes a matrix of size [d,k].
Multivariate polynomials appear in this toolbox mainly as tensor products. Assuming first, for simplicity, that the polynomial in question is scalar-valued but m-variate, this means that its coefficient "list" a is an m-dimensional array, of size [k1,...,km] say, and its value at some m-vector x is, correspondingly, given by
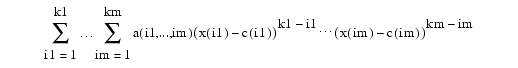
Piecewise-polynomials
A piecewise-polynomial function refers to a function put together from polynomial pieces. If the function is univariate, then, for some strictly increasing sequence 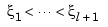 , and for i=1:l, it agrees with some polynomial pi on the interval
, and for i=1:l, it agrees with some polynomial pi on the interval 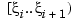 . Outside the interval
. Outside the interval 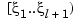 , its value is given by its first, respectively its last, polynomial piece.The
, its value is given by its first, respectively its last, polynomial piece.The 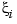 are its breaks. All the multivariate piecewise-polynomials in this toolbox are tensor products of univariate ones.
are its breaks. All the multivariate piecewise-polynomials in this toolbox are tensor products of univariate ones.
B-splines
In this toolbox, the term B-spline is used in its original meaning only, as given to it by its creator, I. J. Schoenberg, and further amplified in his basic 1966 article with Curry, and used in PGS and many other books on splines. According to Schoenberg, the B-spline with knots tj, ..., tj+k is given by the following somewhat obscure formula (see, e.g., IX(1) in PGS):
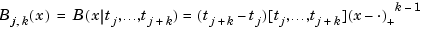
To be sure, this is only one of several reasonable normalizations of the B-spline, but it is the one used in this toolbox. It is chosen so that
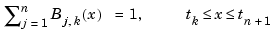
But, instead of trying to understand the above formula for the B-spline, look at the reference pages for the GUI bspligui for some of the basic properties of the B-spline, and use that GUI to gain some first-hand experience with this intriguing function. Its most important property for the purposes of this toolbox is also the reason Schoenberg used the letter B in its name:
Every space of (univariate) piecewise-polynomials of a given order has a Basis consisting of B-splines.
Splines
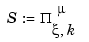
of all (scalar-valued) piecewise-polynomials of order k with breaks 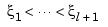 that, for i=2:l, may have a jump across
that, for i=2:l, may have a jump across 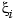 in its
in its 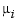 th derivative but have no jump there in any lower order derivative. This set is a linear space, in the sense that any scalar multiple of a function in S is again in S, as is the sum of any two functions in S.
th derivative but have no jump there in any lower order derivative. This set is a linear space, in the sense that any scalar multiple of a function in S is again in S, as is the sum of any two functions in S.
Accordingly, S contains a basis (in fact, infinitely many bases), that is, a sequence f1,...,fn so that every f in S can be written uniquely in the form
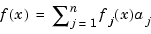
for suitable coefficients aj. The number n appearing here is the dimension of the linear space S. The coefficients aj are often referred to as the coordinates of f with respect to this basis.
In particular, according to the Curry-Schoenberg Theorem, our space S has a basis consisting of B-splines, namely the sequence of all B-splines of the form 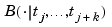 , j=1:n, with the knot sequence t obtained from the break sequence
, j=1:n, with the knot sequence t obtained from the break sequence 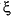 and the sequence µ by the following recipe:
and the sequence µ by the following recipe:
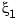 and
and 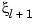 occur in t exactly k times
occur in t exactly k times
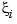 occur in t exactly
occur in t exactly 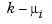 times
times
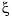
Note the correspondence between the multiplicity of a knot and the smoothness of the spline across that knot. In particular, at a simple knot, that is a knot that appears exactly once in the knot sequence, only the (k-1)st derivative may be discontinuous.
Rational splines
A rational spline is any function of the form r(x) = s(x)/w(x), with both s and w splines and, in particular, w a scalar-valued spline, while s often is vector-valued. In this toolbox, there is the additional requirement that both s and w be of the same form and even of the same order, and with the same knot or break sequence. This makes it possible to store the rational spline r as the ordinary spline R whose value at x is the vector [s(x);w(x)]. It is easy to obtain r from R. For example, if v is the value of R at x, then v(1:end-1)/v(end) is the value of r at x. As another example, consider getting derivatives of r from those of R. Since s = wr, Leibniz' rule tells us that
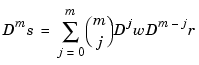
Hence, if v(:,j) contains Dj-1R(x), j=1:m+1, then
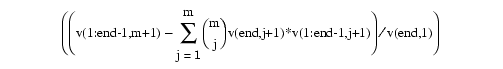
provides the value of Dm r(x).
Thin-plate splines
A bivariate thin-plate spline is of the form
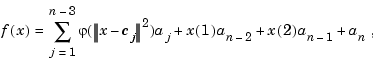
with 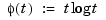 a univariate function, and
a univariate function, and 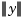 denoting the Euclidean length of the vector y. The sites cj are called the centers, and the radially symmetric function
denoting the Euclidean length of the vector y. The sites cj are called the centers, and the radially symmetric function 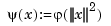 is called the basis function, of this particular stform.
is called the basis function, of this particular stform.
Interpolation
Interpolation is the construction of a function f that matches given data values, yi, at given data sites, xi, in the sense that f(xi) = yi, all i.
The interpolant, f, is usually constructed as the unique function of the form
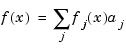
that matches the given data, with the functions fj chosen "appropriately". Many considerations might enter that choice. One of these considerations is sure to be that one can match in this way arbitrary data. For example, polynomial interpolation is popular since, for arbitrary n data points (xi,yi) with distinct data sites, there is exactly one polynomial of order n that matches these data. This says that choosing the fj in the above "model" to be fj(x) = xj-1, j=1:n, guarantees exactly one such interpolant to arbitrary n data points with distinct data sites.
In spline interpolation, one chooses the fj to be the n consecutive B-splines Bj(x) = B(x|tj,...,tj+k), j=1:n, of order k for some knot sequence 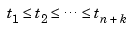 . For this choice, we have the following important theorem.
. For this choice, we have the following important theorem.
Schoenberg-Whitney Theorem
Let x1<x2 < < xn. For arbitrary corresponding values yi, i=1:n, there exists exactly one spline f of order k with knot sequence tj, j=1:n+k, so that
< xn. For arbitrary corresponding values yi, i=1:n, there exists exactly one spline f of order k with knot sequence tj, j=1:n+k, so that 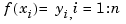 , if and only if the sites satisfy the Schoenberg-Whitney conditions of order k with respect to that knot sequence t, namely
, if and only if the sites satisfy the Schoenberg-Whitney conditions of order k with respect to that knot sequence t, namely
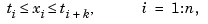
with equality allowed only if the knot in question has multiplicity k, i.e., appears k times in t. In that case, the spline being constructed may have a jump discontinuity across that knot, and it is its limit from the right or left at that knot that matches the value given there.
Least-squares approximation
In least-squares approximation, the data may be matched only approximately. Specifically, the linear system
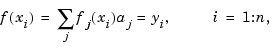
is solved in the least-squares sense. In this, some weighting is involved, i.e., the coefficients aj are determined so as to minimize the error measure
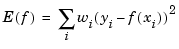
for certain nonnegative weights wi at the user's disposal, with the default being to have all these weights the same.
Smoothing
In spline smoothing, one also tries to make such an error measure small, but tries, at the same time, to keep the following roughness measure small,
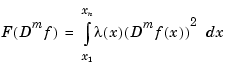
with 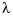 a nonnegative weight function that is usually just the constant function 1, and Dm f the mth derivative of f. The competing claims of small E(f) and small F(Dm f) are mediated by a smoothing parameter, for example, by minimizing
a nonnegative weight function that is usually just the constant function 1, and Dm f the mth derivative of f. The competing claims of small E(f) and small F(Dm f) are mediated by a smoothing parameter, for example, by minimizing
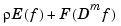
for some choice of 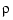 , and over all f for which this expression makes sense.
, and over all f for which this expression makes sense.
Remarkably, if the roughness weight 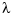 is constant, then the unique minimizer f is a spline of order 2m, with knots only at the data sites, and all the interior knots simple, and with its derivatives of orders m,...,2m-2 equal to zero at the two extreme data sites, the so-called "natural" end conditions. The larger the smoothing parameter
is constant, then the unique minimizer f is a spline of order 2m, with knots only at the data sites, and all the interior knots simple, and with its derivatives of orders m,...,2m-2 equal to zero at the two extreme data sites, the so-called "natural" end conditions. The larger the smoothing parameter 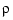 used, the more closely f matches the given data and the larger is its mth derivative.
used, the more closely f matches the given data and the larger is its mth derivative.
For data values yi at sites ci in the plane, one uses instead the error measure and roughness measure
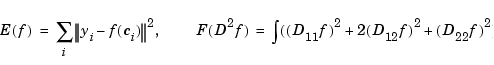
and, correspondingly, the minimizer of the sum 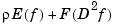 is not a polynomial spline but a thin-plate spline.
is not a polynomial spline but a thin-plate spline.
Note that the unique minimizer of 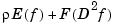 for given
for given 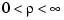 is also the unique minimizer of
is also the unique minimizer of
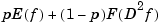 for
for 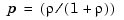 and vice versa.
and vice versa.
| tpaps |