| Real-Time Workshop | |
Using and Configuring Expression Folding
The options described in this section let you control the operation of expression folding.
Enabling Expression Folding
Expression folding operates only on expressions involving local variables. Expression folding is therefore available only when both the Signal storage reuse and Local block outputs code generation options are on.
For a new model, default code generation options are set to use expression folding. If you are configuring an existing model, you can ensure that expression folding is turned on as follows:
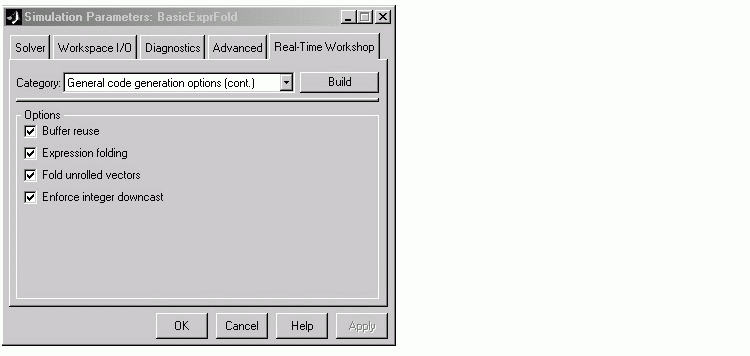
Figure 9-2: Expression Folding Options
Expression Folding Options
This section discusses the available code generation options related to expression folding.
Expression Folding. This option turns the expression folding feature on or off. When Expression folding is selected, the Fold unrolled vectors and Enforce integer downcast options are available.
Alternatively, you can turn expression folding on or off from the MATLAB command line via the command
If val = 1, expression folding is turned on. If val = 0, expression folding is turned off.
Fold Unrolled Vectors. We recommend that you leave this option on, as it will decrease the generated code (ROM) size.
Turning Fold unrolled vectors off will speed up code generation for vector signals whose widths are less than the Loop rolling threshold (SeeLoop Rolling Threshold Field). You may want to consider turning Fold unrolled vectors off if:
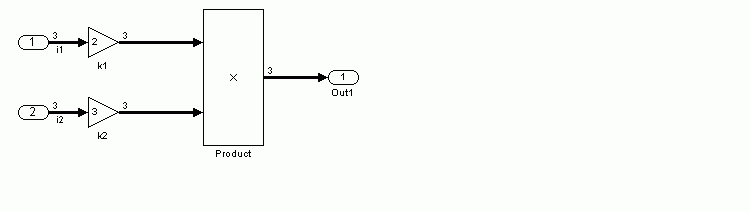
To understand the effect of Fold unrolled vectors, consider the model shown in this diagram.
The input signals i1 and i2 are vectors of width 3. The input signal elements are represented in the generated code as members of the rtU structure (rtU.i1[n] and rtU.i2[n]).
Assuming the model's loop rolling threshold is greater than 3, (the default threshold is 5) computations on i1 are not rolled into a for loop. If Fold unrolled vectors is on, the gain computations for elements of i1 and i2 are folded into the Outport block computations, as shown in this MdlOutputs function.
void MdlOutputs(int_T tid) /* tid is required for a uniform function interface. This system * is single rate, and in this case, tid is not accessed. */ UNUSED_PARAMETER(tid); { /* Outport: <Root>/Out1 incorporates: * Product: <Root>/Product * Gain: <Root>/k1 * Inport: <Root>/In1 * Gain: <Root>/k2 * Inport: <Root>/In2 * * Regarding <Root>/k1: * Gain value: rtP.k1_Gain * * Regarding <Root>/k2: * Gain value: rtP.k2_Gain */ rtY.Out1[0] = ((rtP.k1_Gain * rtU.i1[0]) * (rtP.k2_Gain * rtU.i2[0])); rtY.Out1[1] = ((rtP.k1_Gain * rtU.i1[1]) * (rtP.k2_Gain * rtU.i2[1])); rtY.Out1[2] = ((rtP.k1_Gain * rtU.i1[2]) * (rtP.k2_Gain * rtU.i2[2])); }
If Fold unrolled Vectors is off, computations for elements of i1 and i2 are implemented as separate code statements, with intermediate results stored in temporary variables, as shown in this MdlOutputs function.
void MdlOutputs(int_T tid) { /* local block i/o variables */ real_T rtb_s2[3]; real_T rtb_temp1[3]; /* tid is required for a uniform function interface. This system * is single rate, and in this case, tid is not accessed. */ UNUSED_PARAMETER(tid); /* Gain: '<Root>/k1' incorporates: * Inport: '<Root>/In1' * * Regarding '<Root>/k1': * Gain value: rtP.k1_Gain */ rtb_temp1[0] = rtU.i1[0] * rtP.k1_Gain; rtb_temp1[1] = rtU.i1[1] * rtP.k1_Gain; rtb_temp1[2] = rtU.i1[2] * rtP.k1_Gain; /* Gain: '<Root>/k2' incorporates: * Inport: '<Root>/In2' * * Regarding '<Root>/k2': * Gain value: rtP.k2_Gain */ rtb_s2[0] = rtU.i2[0] * rtP.k2_Gain; rtb_s2[1] = rtU.i2[1] * rtP.k2_Gain; rtb_s2[2] = rtU.i2[2] * rtP.k2_Gain; /* Product: '<Root>/Product' */ rtb_temp1[0] = rtb_temp1[0] * rtb_s2[0]; rtb_temp1[1] = rtb_temp1[1] * rtb_s2[1]; rtb_temp1[2] = rtb_temp1[2] * rtb_s2[2]; /* Outport: '<Root>/Out1' */ rtY.Out1[0] = rtb_temp1[0]; rtY.Out1[1] = rtb_temp1[1]; rtY.Out1[2] = rtb_temp1[2]; }
Enforce Integer Downcast . This option refers to 8-bit operations on 16-bit microprocessors and 8 and 16-bit operations on 32-bit microprocessors. To ensure consistency between simulation and code generation, the results of 8 and 16-bit integer expressions must be explicitly downcast.
Deselecting this option improves code efficiency. However, the primary effect of deselecting this option is that expressions involving 8 and 16-bit arithmetic are less likely to overflow in code than they are in simulation. We recommend that you turn on Enforce integer downcast for safety. Turn the option off only if you are concerned with generating the smallest possible code, and you know that 8 and 16-bit signals will not overflow.
As an example, consider this model.
The following code fragment shows the output computation (within the MdlOutputs function) when Enforce integer downcast is on. The Gain blocks are folded into a single expression. In addition to the typecasts generated by the Type Conversion blocks, each Gain block output is cast to int8_T.
int8_T rtb_Data_Type_Conversion; . . . rtY.Out1 = (int16_T)(int8_T)(rtP.Gain2_Gain * (int8_T)(rtP.Gain1_Gain * (int8_T)(rtP.Gain_Gain * rtb_Data_Type_Conversion)));
If Enforce integer downcast is off, the code contains only the typecasts generated by the Type Conversion blocks, as shown in the following code fragment.
int8_T rtb_Data_Type_Conversion; . . . rtY.Out1 = (int16_T)(rtP.Gain2_Gain * (rtP.Gain1_Gain * (rtP.Gain_Gain * rtb_Data_Type_Conversion)));
| | Expression Folding Example | Supporting Expression Folding in S-Functions | |