| Mathematics | |
指数近似
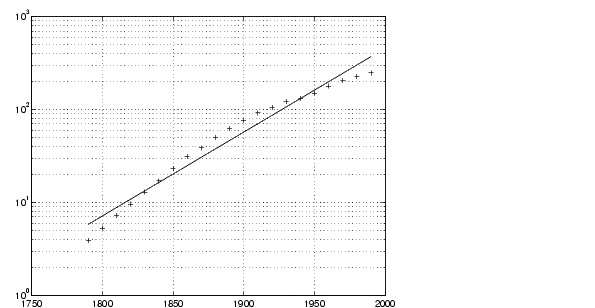
前のページで人口データのプロットを調べると、人口データ曲線は、見た目で、わずかですが指数的に見えます。この見え方を利用して、正規化された年に対する人口値の対数データでフィットして見ましょう。
logp1 = polyfit(sdate,log10(pop),1); logpred1 = 10.^polyval(logp1,sdate); semilogy(cdate,logpred1,'-',cdate,pop,'+'); grid on
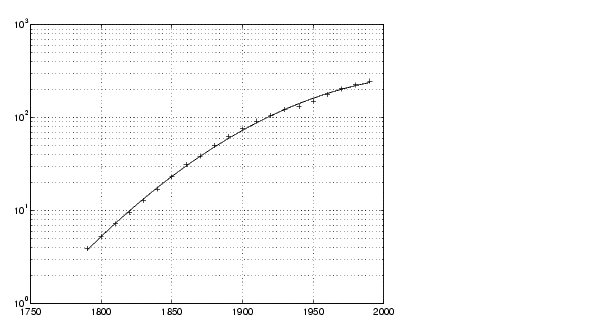
logp2 = polyfit(sdate,log10(pop),2); logpred2 = 10.^polyval(logp2,sdate); semilogy(cdate,logpred2,'-',cdate,pop,'+'); grid on
これは、よりフィットしたモデルになります。プロットの中の上限部は先細りになっているように見え、一方、下限部の多項式フィットは、無限まで連続で、凸型になっています。
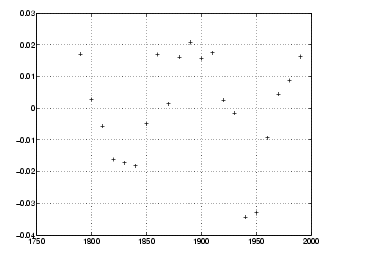
| Residuals in Log Population Scale |
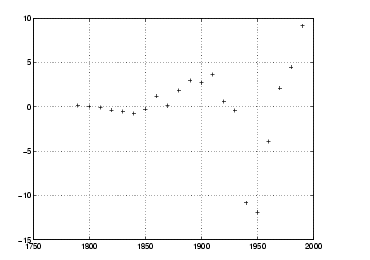
Residuals in Population Scale |
logres2 = log10(pop) - polyval(logp2,sdate);plot(cdate,logres2,'+') |
r = pop - 10.^(polyval(logp2,sdate));plot(cdate,r,'+') |
残差は、単純な多項式適合よりもランダムです。期待したように、残差は人口が増えるに従って大きくなります。しかし、全体的に、対数モデルは、人口データにより精度良くフィットします。
| | 残差の解析 | 誤差の範囲 | |