

| Partial Differential Equation Toolbox | |
Nonlinear Equations
The low-level functions of the PDE Toolbox are aimed at solving linear equations. Since many interesting computational problems are nonlinear, the toolbox contains a nonlinear solver built on top of the assempde function.
The basic idea is to use Gauss-Newton iterations to solve the nonlinear equations. Say you are trying to solve the equation
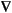 · (c(u)u) + a(u)u - f(u) = 0.
· (c(u)u) + a(u)u - f(u) = 0.
In the FEM setting you solve the weak form of r(u) = 0. Set as usual
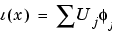
then, multiply the equation by an arbitrary test function 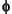 i, integrate on the domain
i, integrate on the domain 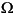 , and use Green's formula and the boundary conditions to obtain
, and use Green's formula and the boundary conditions to obtain
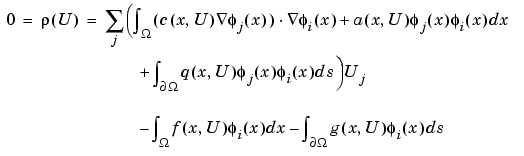
which has to hold for all indices i.
The residual vector  (U) can be easily computed as
(U) can be easily computed as
(U) = (K + M + Q)U - (F + G)
where the matrices K, M, Q and the vectors F and G are produced by assembling the problem
· (c(U)u) + a(U)u = f(U)
Assume that you have a guess U(n) of the solution. If U(n) is close enough to the exact solution, an improved approximation U(n + 1) is obtained by solving the linearized problem
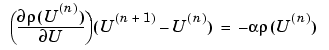
where  is a positive number. (
is a positive number. (It is not necessary that (U)=0 have a solution even if (u) = 0 has. In this case, the Gauss-Newton iteration tends to be the minimizer of the residual, i.e., the solution of minU ||(U)||).
It is well known that for sufficiently small
(U(n + 1))|| < ||(U(n))||
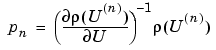
is called a descent direction for ||(U)||, where ||· || is the l2-norm. The iteration is
pn
where  1 is chosen as large as possible such that the step has a reasonable descent.
1 is chosen as large as possible such that the step has a reasonable descent.
The Gauss-Newton method is local, and convergence is assured only when U(0) is close enough to the solution. In general, the first guess may be outside the region of convergence. To improve convergence from bad initial guesses, a damping strategy is implemented for choosing , the Armijo-Goldstein line search. It chooses the largest damping coefficient out of the sequence 1, 1/2, 1/4, . . . such that the following inequality holds:
(U(n))|| - ||(U(n)+ pn)|| 
 ||(U(n))||
||(U(n))||
which guarantees a reduction of the residual norm by at least 1 - /2. Note that each step of the line-search algorithm requires an evaluation of the residual (U(n)+ pn).
An important point of this strategy is that when U(n) approaches the solution, then 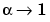 and thus the convergence rate increases. If there is a solution to (U) = 0, the scheme ultimately recovers the quadratic convergence rate of the standard Newton iteration.
and thus the convergence rate increases. If there is a solution to (U) = 0, the scheme ultimately recovers the quadratic convergence rate of the standard Newton iteration.
Closely related to the above problem is the choice of the initial guess U(0). By default, the solver sets U(0) and then assembles the FEM matrices K and F and computes
The damped Gauss-Newton iteration is then started with U(1), which should be a better guess than U(0). If the boundary conditions do not depend on the solution u, then U(1) satisfies them even if U(0) does not. Furthermore, if the equation is linear, then U(1) is the exact FEM solution and the solver does not enter the Gauss-Newton loop.
There are situations where U(0) = 0 makes no sense or convergence is impossible.
In some situations you may already have a good approximation and the nonlinear solver can be started with it, avoiding the slow convergence regime. This idea is used in the adaptive mesh generator. It computes a solution 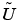 on a mesh, evaluates the error, and may refine certain triangles. The interpolant of
on a mesh, evaluates the error, and may refine certain triangles. The interpolant of 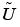 is a very good starting guess for the solution on the refined mesh.
is a very good starting guess for the solution on the refined mesh.
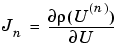
is not available. Approximation of Jn by finite differences in the following way is expensive but feasible. The ith column of Jn can be approximated by
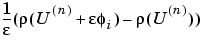
which implies the assembling of the FEM matrices for the triangles containing grid point i. A very simple approximation to Jn, which gives a fixed point iteration, is also possible as follows. Essentially, for a given U(n), compute the FEM matrices K and F and set
This is equivalent to approximating the Jacobian with the stiffness matrix. Indeed, since (U(n)) = KU(n) - F, putting Jn = K yields
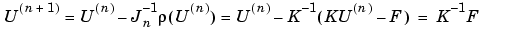
In many cases the convergence rate is slow, but the cost of each iteration is cheap.
The nonlinear solver implemented in the PDE Toolbox also provides for a compromise between the two extremes. To compute the derivative of the mapping 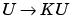 , proceed as follows. The a term has been omitted for clarity, but appears again in the final result below.
, proceed as follows. The a term has been omitted for clarity, but appears again in the final result below.
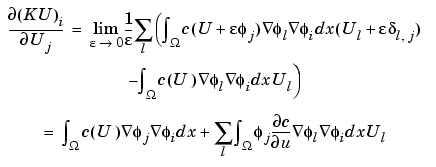
The first integral term is nothing more than Ki,j.
The second term is "lumped," i.e., replaced by a diagonal matrix that contains the row sums. Since 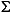 jj = 1, the second term is approximated by
jj = 1, the second term is approximated by
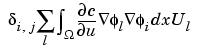
which is the ithcomponent of K(c')U, where K(c') is the stiffness matrix associated with the coefficient
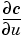 rather than c. The same reasoning can be applied to the derivative of the mapping
rather than c. The same reasoning can be applied to the derivative of the mapping 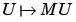 . Finally note that the derivative of the mapping
. Finally note that the derivative of the mapping 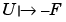 is exactly
is exactly
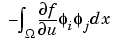
which is the mass matrix associated with the coefficient
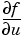 . Thus the Jacobian of the residual (U) is approximated by
. Thus the Jacobian of the residual (U) is approximated by
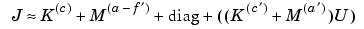
where the differentiation is with respect to u. K and M designate stiffness and mass matrices and their indices designate the coefficients with respect to which they are assembled. At each Gauss-Newton iteration, the nonlinear solver assembles the matrices corresponding to the equations
· (cu) + (a - f') u = 0 and - · (c'u) + a'u = 0
and then produces the approximate Jacobian. The differentiations of the coefficients are done numerically.
In the general setting of elliptic systems, the boundary conditions are appended to the stiffness matrix to form the full linear system:
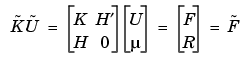
where the coefficients of 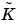 and
and 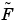 may depend on the solution
may depend on the solution 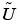 . The "lumped" approach approximates the derivative mapping of the residual by
. The "lumped" approach approximates the derivative mapping of the residual by
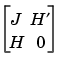
The nonlinearities of the boundary conditions and the dependencies of the coefficients on the derivatives of 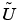 are not properly linearized by this scheme. When such nonlinearities are strong, the scheme reduces to the fix-point iteration and may converge slowly or not at all. When the boundary conditions are linear, they do not affect the convergence properties of the iteration schemes. In the Neumann case they are invisible (H is an empty matrix) and in the Dirichlet case they merely state that the residual is zero on the corresponding boundary points.
are not properly linearized by this scheme. When such nonlinearities are strong, the scheme reduces to the fix-point iteration and may converge slowly or not at all. When the boundary conditions are linear, they do not affect the convergence properties of the iteration schemes. In the Neumann case they are invisible (H is an empty matrix) and in the Dirichlet case they merely state that the residual is zero on the corresponding boundary points.
| | The Eigenvalue Equation | Adaptive Mesh Refinement | |