

| Model Browser User's Guide | |
Statistics
Let A be the matrix such that the weights are given by 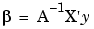 where X is the regression matrix. The form of A varies depending on the basic fit algorithm employed.
where X is the regression matrix. The form of A varies depending on the basic fit algorithm employed.
In the case of ordinary least squares, we have A = X'X.
For ridge regression (with regularization parameter 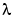 ), A is given by A = X'X +
), A is given by A = X'X + 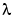 I.
I.
The most complicated situation is for the Rols algorithm. Recall that during the Rols algorithm X is decomposed using the Gram-Schmidt algorithm to give X = WB, where W has orthogonal columns and B is upper triangular. The corresponding matrix A for Rols is then 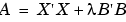 .
.
The matrix 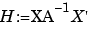 is called the hat matrix, and the leverage of the ith data point hi is given by the ith diagonal element of H. All the statistics derived from the hat matrix, for example, PRESS, studentized residuals, confidence intervals, and Cook's distance, are computed using the hat matrix appropriate to the particular fit algorithm.
is called the hat matrix, and the leverage of the ith data point hi is given by the ith diagonal element of H. All the statistics derived from the hat matrix, for example, PRESS, studentized residuals, confidence intervals, and Cook's distance, are computed using the hat matrix appropriate to the particular fit algorithm.
| | Prune Functionality | GCV Criterion | |